Releasing code updates in a production service with hundreds or even thousands of users using the application and expecting zero downtime is a full-time job for many of us.
Luckily we have many deployment strategies from where we can choose, picking the right one for your project is an important decision that has to be agreed upon with your development team.
Manual Deployment (copy and paste) Link to heading

This is the most simple way of deployment which consists in fetching the source code from a repository (manually) to the server.
A typical workflow is:
- A developer commit and push changes to a repository
- Developer SSH into the server
- Developer git pull from the repository to the server
- Developer restart the webserver
All the steps are manually executed by the developer. The only scenario where this approach makes sense is when a single developer starts building a prototype. In any other case this is not recommended.
Big Bang Deployment (all at once) Link to heading
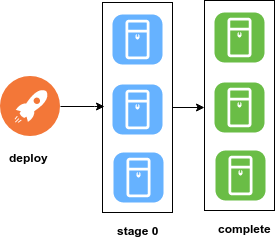
This approach is not so different from the previous one because it deploys the application to a single server or multiple ones all at once. There is usually a tool that automates the deployment process but we are still lacking a deployment pipeline. If something goes wrong or a bug is introduced in the application users will experience downtime. Not recommended in a production environment but is a common way of deployment in a development environment where developers need to see code changes fast.
E.g.
Three servers deployed all at once
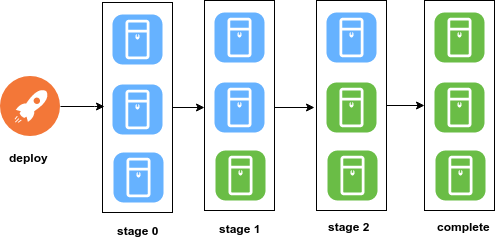
Rolling Deployment Link to heading
This the default deployment type of Kubernetes because of the versatility to gradually deploy our changes to production. During the deployment the new and old versions coexist without affecting functionality or user experience. This process makes it easier to roll back if something is not quite right.
E.g.
The following diagram shows three servers where blue represents a server with the current version of the code while green represents a server with the new version of the code.
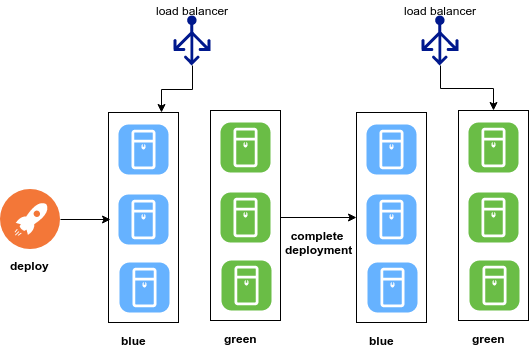
Blue/Green Deployment Link to heading
This is one of the most popular ways to deploy in a production environment. Blue/Green deployment creates a clone from the current environment. Is in the new environment (green) where the new revision of the code is deployed, we can make tests without disturbing the current running environment (blue). Once we are happy with the results we can complete and route the traffic and make the green environment the default while deleting the blue environment. To succeed with this approach we need to rely heavily on automation.
Advantages Link to heading
- Zero downtime
- Quickly rollback if something goes wrong
- Testing in a live environment before releasing to the users
Disadvantages Link to heading
- hard to implement in a non-cloud platform
- Expensive
- Hard to implement if the green environment needs to write to the Database
E.g.
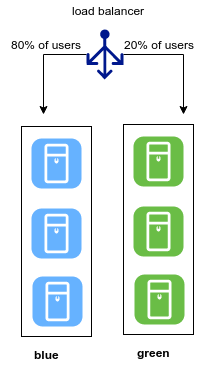
Canary Deployment Link to heading
It has the same characteristics of Green/Deployment (cloning) but gradually sends user traffic to the green environment.
Advantages Link to heading
All the benefits of Blue/Green plus:
- Use to test new features and make a gradual assessment of stability.
- Real time users feedback.
Disadvantages Link to heading
- Complexity
- Expensive if we leave both environments running for a long time.
E.g.