HA Kubernetes Link to heading
One of the reasons for using Kubernetes in the first place is to have a high available, fully scalable application so the users can experience a smoothly interaction with the application.
Out of the box, Kubernetes and all the components are ready meant to be HA. In this post, we are going to explore the best ways to achieve HA in Kubernetes.
Making your apps Highly Available Link to heading
Making your apps HA is simple when using Kubernetes. Kubernetes takes care of almost everything, but still, there is the risk of the servers running Kubernetes going down.
Making Kubernetes Master HA Link to heading
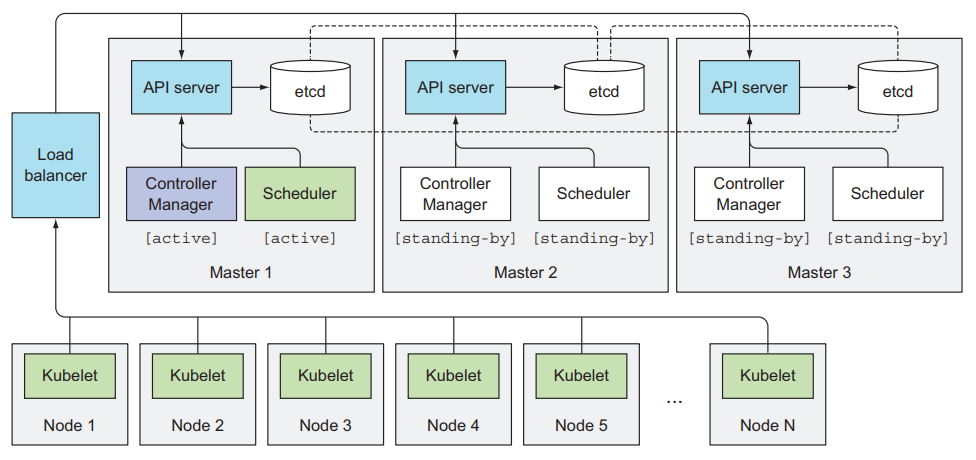
The way to have an HA cluster is obvious, having multiple servers running the Control Plane components.
- etcd
- API Server
- Controller Manager
- Scheduler
HA etcd Link to heading
etcd is a distributed system by default. All we need to do is to run the appropriate number of machines and make them aware of each other. The number of machines has to be an odd number (three, five or seven).
The odd number of nodes is because, of the quorum. For a cluster of N machines, the quorum is (n/2)+1. For an odd-number cluster, adding one node will always increase the number of nodes necessary for a quorum.
Then, having an even number of machines makes the fault tolerance worse since exactly the same number of nodes may fail without losing quorum but there are more nodes that can fail.
For a better insight check the Raft Consensus Algorithm.
| Machines | Quorum | Fault Tolerance |
|---|---|---|
| 1 | 1 | 0 |
| 2 | 2 | 0 |
| 3 | 2 | 1 |
| 4 | 3 | 1 |
| 5 | 3 | 2 |
| 6 | 4 | 2 |
| 7 | 4 | 3 |
Having more than seven machines running etcd impacts performance.
HA API Server Link to heading
The API Server is stateless (all data stored in etcd), just by adding more nodes to the API Server we can achieve High Availability. To make things simpler they don’t need to be aware of each other. By having multiple API Servers we need to have a load balancer in front of them, in this case, the other components like the kubelet communicates directly to the load balancer endpoint.
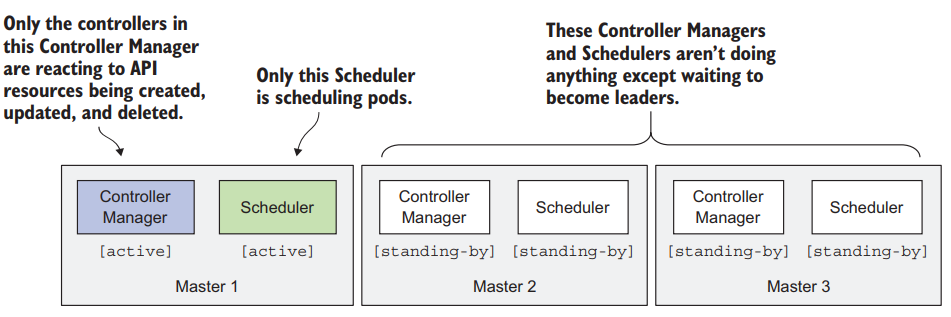
HA Controllers & Scheduler Link to heading
This is harder than HA API Server because these controllers continuously watch the cluster state and act when it changes, possibly modifying the cluster state. We don’t want multiple or unintended modifications to the state of the cluster. This is solved by choosing a leader and stand-by solution.