Learning Kubernetes (k8 for short) is already complex, to make it even funnier I decided to go one level below and learn (or try) how this container orchestrator works behind scenes.
Most of the references come from blogs like Julia Evans, Kubernetes Documentation and this awesome book called Kubernetes in Action
K8 Architecture Summary Link to heading
In a nutshell, k8 has two components
1. Control Plane (master node)
- API Server
- Scheduler
- Control Manager
- etcd (key-value storage)
2. The (worker) Nodes
- Kubelet
- Kube Proxy
- Container Runtime (docker or others)
- add-ons
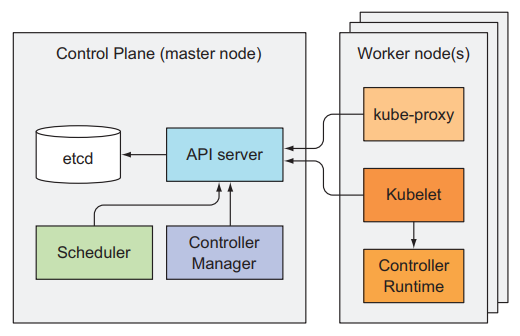
How these components communicate? Link to heading
To summarize:
- All components communicate with the API server.
- They don’t talk to each other directly.
- Only the API server communicates with etcd.
- Communication between the API server and the other components are initiated by the components, except when we run
kubectlto get logs ,kubectl attachto connect to a running container. In those cases the API Server connects to the kubelet.
How components are run Link to heading
The kubelet is one of the most interesting components of the system because is the only one that always runs as a regular system processes. All the other components in the Control plane and Worker nodes can run as pods or system process. The kubelet is also deployed to the Master node to run the Control Plane components as pods.
etcd knows everything about your cluster Link to heading
All objects configurations are stored in etcd.
For instance, all the operations for retrieving information about the cluster such as kubectl get nodes, kubectl get pods, etc. starts with a call to the API Server and then the API Server reads the information from etcd.
The same happens when we make a change in the cluster like adding a new pod kubectl create -f new-pod.yaml. The API Server is called and this interacts with etcd to write the new state of the cluster.
The API Server talks with everyone Link to heading
It is basically a CRUD system (create, read, update, delete) with a RESTful API endpoint and its database is the etcd service.
It also validates the objects before storing to etcd. It uses Optimistic Locking to ensure that two clients don’t update objects at the same time.
The API Server uses Authentication plugins to authenticate the user, after the plugin identifies the user, extracts the userid and group, this data is used by the Authorization Plugin to identify if the user can perform the action on the requested resource. After the plugin says that the user can perform the action a request is sent to the Admision Control Plugin. In Summary:
Authentication Plugin –> Authorization Plugin –> Adminision Control Plugin
After all this process the API Server validates the object and stores the state in etcd and returns a response to the client.
The Scheduler is always watching the API Server Link to heading
The Scheduler has a watch mechanism and waits for newly created pods through the API Server, then assign the new pod to a node. The Scheduler does not communicate with the node server or kubelet, all the Scheduler does is update the pod definition through the API Server.
So far seems like a simple task if the Scheduler just picks a random node to schedule the pod but actually, the Scheduler uses algorithms to pick the best node.
Algorithm flow:
- Filter nodes to obtain the acceptable nodes.
- Chose the best one based on the highest score, if all have the same score, round-robin is used.
Acceptable Nodes Questions:
- Can the Node fulfill the pod request for Hardware resources?
- If the pod request to run in a particular node, is this the node?
- If the pod request to mount a volume, can this volume be mounted in this node?
- Does the pod tolerate the taints of the node?
Pods belonging to the same Service or ReplicaSet are spread across multiple nodes by default, but this is not guaranteed. We can force the pods to be spread across the cluster or kept together by defining pod affinity rules.
The Control Manager has multiple controllers Link to heading
There is a controller for almost every resource you can create. The list of these controllers include:
- Replication manager
- ReplicaSet, DaemonSet and Job controllers
- Deployment controller
- StatefulSet controller
- Node controller
- Service controller
- NameSpace controller
- PersistentVolume controller
- Others
What they do and how they do it?
Controllers watch the API Server for changes in resources (Deployments, Services, etc) and perform operations for each change. They don’t communicate with the kubelet directly or issue any instructions to them, they just update a resource in the API Server
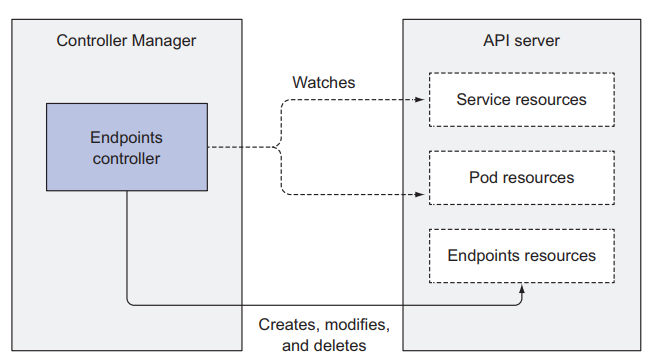
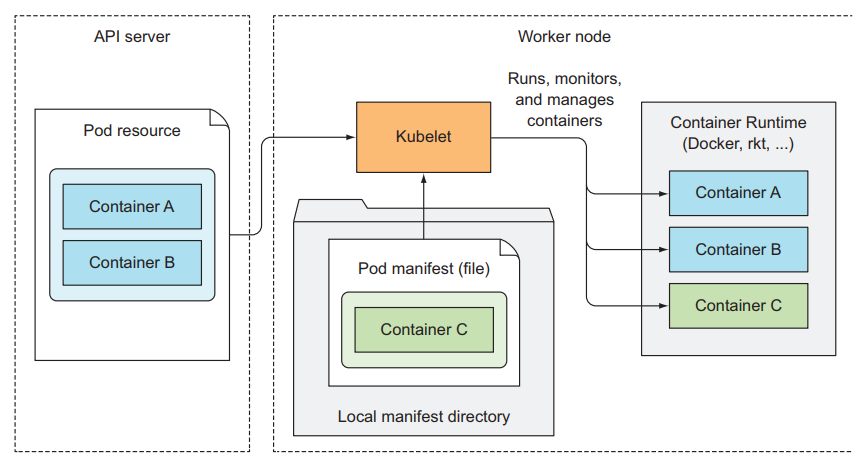
The Kubelet is not a pod but creates multiple ones Link to heading
- Its initial job is to register the node where is running by creating a Job Resource in the API Server.
- Then monitor the API Server for Pods that have been scheduled in the node, and start the pod container (container runtime).
- Constantly monitors running containers and report their status to the API Server
Running static pods without talking to the API Server is also possible. Actually, this is how the master nodes run the control plane pods. in summary, the kubelet runs pods based on pods specs from the API Server and a local file directory (Kubelet manifest Directory).
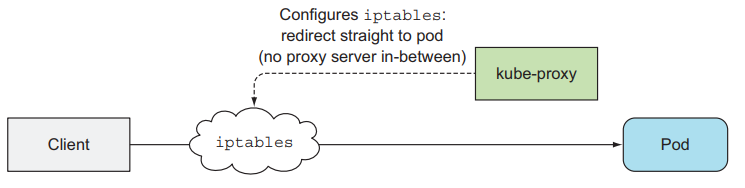
Kube-Proxy does Networking Link to heading
The kube-proxy makes sure connections to the service IP and ports are routed to the right pod. When the service has multiple pods, kube-proxy performs load balancing across those pods.
Two proxy modes:
- userspace proxy mode
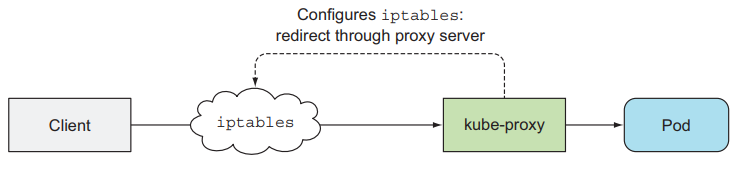
- iptables proxy mode (better performance)
And finally, we have the add-ons Link to heading
Extra features like the Kubernetes Dashboard and DNS lookup for Services.